Introducing SparkID: fast, sortable, compact unique IDs
If you’ve ever built a web application, you’ve almost certainly had to generate unique IDs. Maybe you needed primary keys for your database rows, or unique identifiers for API resources, or trace IDs for your logging pipeline. The two most popular choices today are UUIDs and nanoid, and both get the job done. But both come with tradeoffs that have bugged me for a while. Let me explain.
Why existing ID generators fall short
UUID v7
UUID v7 is the latest UUID standard and a real improvement over its predecessors. It embeds a timestamp, which means IDs sort in roughly chronological order. That alone makes it a solid choice for database primary keys. But UUIDs have always been awkward to work with in practice.
They’re 36 characters long, including four hyphens: 019553e6-a9b7-7803-9ea4-ceae2f3e7d0f. That’s a lot of characters to pass around in URLs, log lines, and API responses. And those hyphens are a constant source of friction. Try double-clicking a UUID to select it and you’ll only grab one segment. Want to copy the whole thing? You have to carefully click and drag, or triple-click and hope you don’t grab surrounding whitespace. It’s a small annoyance that adds up when you’re debugging or grepping through logs all day.
nanoid
nanoid takes a different approach. It generates short, random, URL-friendly IDs and lets you configure the length and alphabet. It’s fast and compact, which is why it’s become so popular. But nanoid IDs are purely random, and that has real consequences.
The most obvious one is that you can’t sort by ID to get chronological order. If you want to display records in creation order, you need a separate timestamp column and an index to go with it. But the deeper problem is performance. Most databases store rows in a B+ tree ordered by primary key. When your primary keys are sequential, new rows get appended to the end of the tree, and the database can fill pages to about 94% capacity. When your primary keys are random, new rows land on random pages scattered across the tree, causing frequent page splits and dropping page utilization to as low as 50%. On large tables, this means almost every insert has to read a page from disk before writing to it, doubling the I/O cost. Time-sorted IDs avoid this entirely by keeping inserts at the “hot” end of the tree.
nanoid’s default alphabet also includes characters that are easy to misread: lowercase l, uppercase O, hyphens, and underscores. If you’ve ever tried to copy an ID out of a log or read one aloud to a coworker, you know how frustrating this can be. “Was that an l or a 1? Is that an O or a 0?”
Snowflake IDs
Twitter’s Snowflake format is another popular approach: a 64-bit integer split into a 41-bit timestamp, a 10-bit node ID, and a 12-bit sequence number. Discord and Instagram both use variations of it. It’s compact and sortable, but it was designed for a very specific kind of infrastructure.
The 10-bit node ID means every machine that generates IDs needs to be assigned a unique number from 0 to 1,023. That requires some kind of central registry, like the ZooKeeper cluster Twitter used, to make sure no two machines end up with the same node ID. If they do, you get silent collisions.
The 12-bit sequence number also means each node can only generate 4,096 IDs per millisecond before it has to stall and wait for the clock to tick forward. That’s fine for most use cases, but it’s a hard ceiling baked into the format.
ULID
ULID gets closer to the mark: it’s time-sortable, avoids hyphens, and at 26 characters it’s shorter than UUIDs. But it’s still longer than it needs to be, and the reason comes down to encoding.
ULID uses Crockford’s Base32, which only encodes 5 bits per character. A more compact encoding like Base58 gets you about 5.86 bits per character, which is enough to pack the same amount of information into 22 characters instead of 26.
Introducing SparkID
Each of these formats gets something right, but none of them check every box. I wanted compact IDs like nanoid, time-sortability like UUID v7, no coordination like ULID, and strict monotonic ordering even within the same millisecond — along with IDs that are genuinely easy to read and copy. That’s why I built SparkID.
SparkID generates 21-character IDs using the Base58 alphabet, which specifically excludes 0, O, I, and l. No visual ambiguity, no hyphens, no underscores. Just clean, alphanumeric strings.
Here’s what it looks like in practice:
import { generateId } from "sparkid";
const id = generateId(); // "1ocmpHE1bFnygEBAPTzMK"from sparkid import generate_id
id = generate_id() # "1ocmpHE1bFnygEBAPTzMK"use sparkid::SparkId;
let id = SparkId::new(); // "1ocmpHE1bFnygEBAPTzMK"The library is available in JavaScript, Python, and Rust, and all three implementations are consistent in their behavior and ID format.
Performance
All of this extra structure might sound like it comes at a performance cost. In practice, the opposite is true. I benchmarked SparkID against UUID v4, UUID v7, nanoid, and ulid across all three languages, and SparkID was the fastest in every one of them.
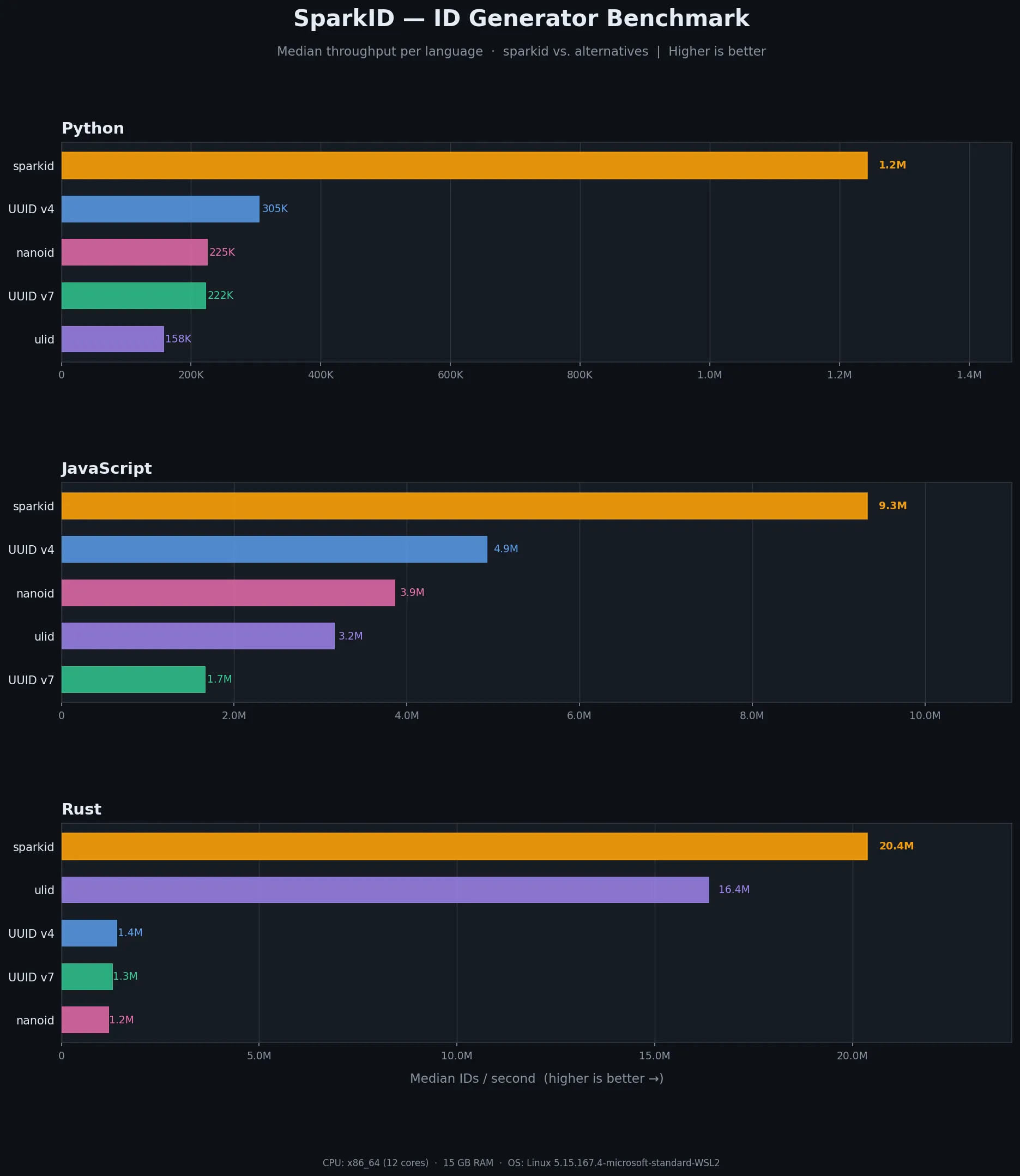
In JavaScript, SparkID generates 9.9 million IDs per second, roughly 2x faster than UUID v4 and nanoid. In Python, it hits 1.2 million IDs per second, about 4x faster than UUID v4. And in Rust, SparkID produces nearly 20 million IDs per second, over 15x faster than UUID v4 and nanoid. If you’d like to run the benchmarks yourself, the benchmark script is in the repo.
A big part of what makes this possible is that SparkID batches its random byte generation. Instead of calling into the system’s cryptographic random number generator for every single ID, it generates random bytes in large batches (16KB at a time in JavaScript and Rust) and pulls from that pool as needed. The JavaScript and Python implementations also cache a pre-concatenated prefix string so that the common case of generating another ID within the same millisecond is just a quick counter increment and a string concatenation. In Rust, the SparkId type is a stack-allocated [u8; 21], which means generating an ID involves zero heap allocation.
Under the hood
Anatomy of a SparkID
Every SparkID is structured as three parts:
[8-char timestamp][6-char counter][7-char random]
For example, given the SparkID 1ocmpHE1bFnygEBAPTzMK:
1ocmpHE1 bFnygE BAPTzMK
──────── ────── ───────
timestamp counter random
The timestamp is the current time in milliseconds since the Unix epoch, encoded in Base58. This is what makes SparkIDs sortable across time. An ID generated at a later millisecond will always sort after one generated at an earlier millisecond. The timestamp won’t overflow until the year 6028, so we have plenty of room.
The counter is what gives SparkID its strict monotonicity guarantee. At the start of each millisecond, the counter is seeded with a random value. For every subsequent ID generated within that same millisecond, the counter increments. This means two IDs generated in the same millisecond, in the same process, will always sort in the order they were created.
The random tail is 7 characters of cryptographically secure randomness, unique to each ID. This is what prevents collisions across different processes and machines.
Collision resistance
A natural question when looking at a new ID format is: how likely are collisions? This comes down to how many bits of entropy each ID has within a given millisecond.
UUID v7 has 128 total bits, but 48 are used for the timestamp, 4 for the version, and 2 for the variant. That leaves 74 bits of randomness per ID, or possible values per millisecond.
SparkID has 13 Base58 characters of entropy per millisecond (6 for the counter seed and 7 for the random tail). Each Base58 character encodes about 5.86 bits, which gives us roughly 76 bits of entropy, or possible values per millisecond. That’s about 4 times more unique values per millisecond than UUID v7, despite SparkID being 15 characters shorter.
Rejection sampling
Converting random bytes to Base58 characters requires some care. The naive approach is to use the modulo operator: byte % 58. But 256 doesn’t divide evenly by 58, so some characters would show up slightly more often than others. SparkID avoids this modulo bias by using rejection sampling. Each random byte is masked to 6 bits (values 0 through 63), and any value 58 or above is simply discarded. The result is a perfectly uniform distribution across the Base58 alphabet.
Thread and fork safety
An ID generator with a monotonic counter is inherently stateful, so concurrency needs to be handled carefully. Each language takes a different approach based on its concurrency model. JavaScript is single-threaded, so a single process-wide generator is all that’s needed. Python uses threading.local to give each thread its own generator and registers a fork handler with os.register_at_fork to reset state in child processes. Rust uses thread_local! storage. In both Python and Rust, if you need process-wide monotonicity across threads, you can wrap a single generator in a Lock or Mutex.
Getting started
Install SparkID with your favorite package manager:
npm install sparkid # JavaScript / TypeScript
pip install sparkid # Python
cargo add sparkid # RustAll three implementations are production-ready, well-tested, and have zero runtime dependencies (Rust’s only dependency is rand for its cryptographically secure random number generator). You can find the source on GitHub and the packages on npm, PyPI, and crates.io.
If you’re looking for unique IDs that sort by creation time, fit neatly in URLs, and are easy on the eyes, give SparkID a try.
